
렌더링/쉐이딩/라이팅의 여정
Realtime Light를 어떻게 다룰거냐? 에 따라 Forward / Deferred 가 나뉨
- Realtime : 실시간 연산, 동적 라이팅
- 여기서 Baked 는 논외
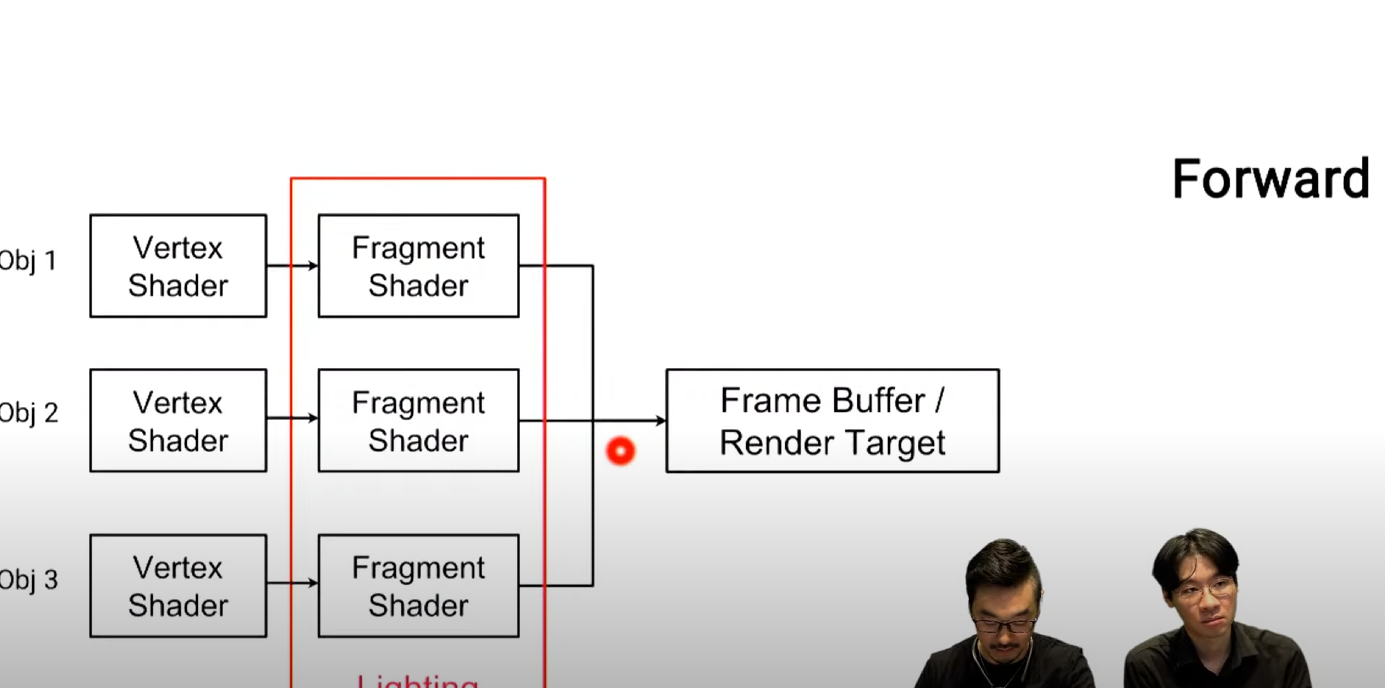
Forward Rendering
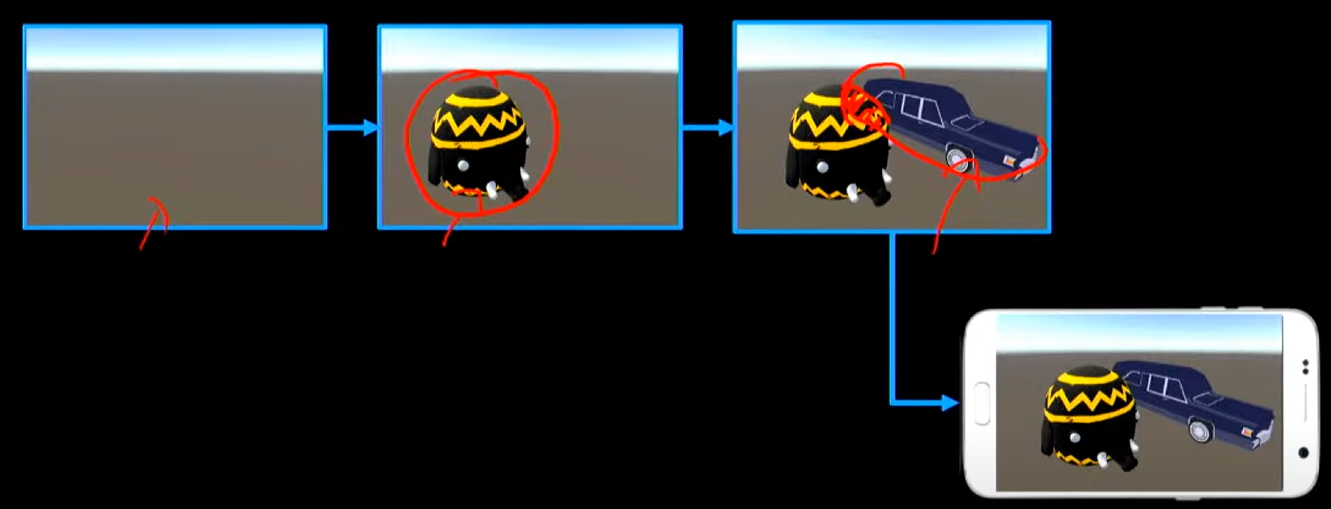
전통적인 라이팅 기법
위의 그림처럼 앞에 있는 친구 먼저 그리고 뒤에 차를 그리기 때문에
겹치는 부분만큼 픽셀 연산을 건너뛸 수 있다!
Depth Buffer

여기서 1이 위 그림의 펭귄, 2가 자동차라고 보면 됨
Depth Buffer는 불투명 오브젝트만 가능하다
Order In Layer 기능은 이거랑 관계 없이 렌더링 순서로 작동
Double Buffering

렌더링 순서대로 화면에 보이는 게 아니라 모든 렌더링이 완료된 화면이 뿅하고 모니터에 나올 수 있게 해줌
렌더링 파이프라인을 거친 친구들 -> Back Buffer(보이지 않고 내부적으로 메모리로 갖고만 있는 버퍼)로 감
다 그리고나면 Front Buffer로 바꿔줌, Display로 연결
매프레임 하다보면 Back <-> Front Buffer가 스와핑됨 계속 하나는 그리고 하나는 보여주고 이런 식으로
요즘 세상에는 Triple Buffering이 된다고 한다
Multi Lights in Single-Pass VS Multi Lights in Multi-Passes
Built In(Multi-Passes)
Multi Lights in Multi-passes 사용
많은 빛을 다루려면 그만큼의 패스 필요
가장 강한 빛(Intensity 기준)부터 누적되면서 그림(빛 위에 빛을 덧그림)

한 오브젝트당 5번씩 그리면서 이런 일이 일어나버림
프레임 버퍼에 계속 누적시키면서 그리면 대역폭 문제로도 연결이 됨
읽고, 쓰고를 50번 반복 -> Legacy 비추
URP(Single-Pass)

Shader 내에서 빛 연산을 다 끝내고 쓰기 때문에 오버드로우 이슈가 깔끔해짐
Loop를 돌면서 처리하기 때문에 한 번의 드로우콜로 라이트 처리 가능 (밑의 for문)
연산 효율이 좋다!

여기서 Per Object Limit은 위 사진의 lightsCount의 Limit
오브젝트 하나에 몇 개의 빛을 박을 수 있는가??
이걸 조절한다고해서 DrawCall이 바뀌지는 않고, 오버드로우에도 영향 X Shading 연산에만 영향을 미침

왼쪽이 Vertex / 오른쪽이 Pixel
Additional Lights를 Per Pixel로 하면 예뻐지지만 그만큼 Pixel 연산이 들어가기 때문에 성능은 떨어짐
Per Vertex로 하면 성능은 좋아지지만 좀 안 예쁨,,
결론
수 많은 동적 라이트를 다룰 때는 한계가 있음
멀티 패스로 성능을 포기 하거나, (Built In)
싱글 패스로 라이트를 제한하거나 (URP)
Deferred Rendering
Forward Rendering의 단점을 보완하기 위해 나옴
수많은 동적 라이트를 다루는 기법
라이팅을 지연시킨다는 의미에서 Deferred Rendering

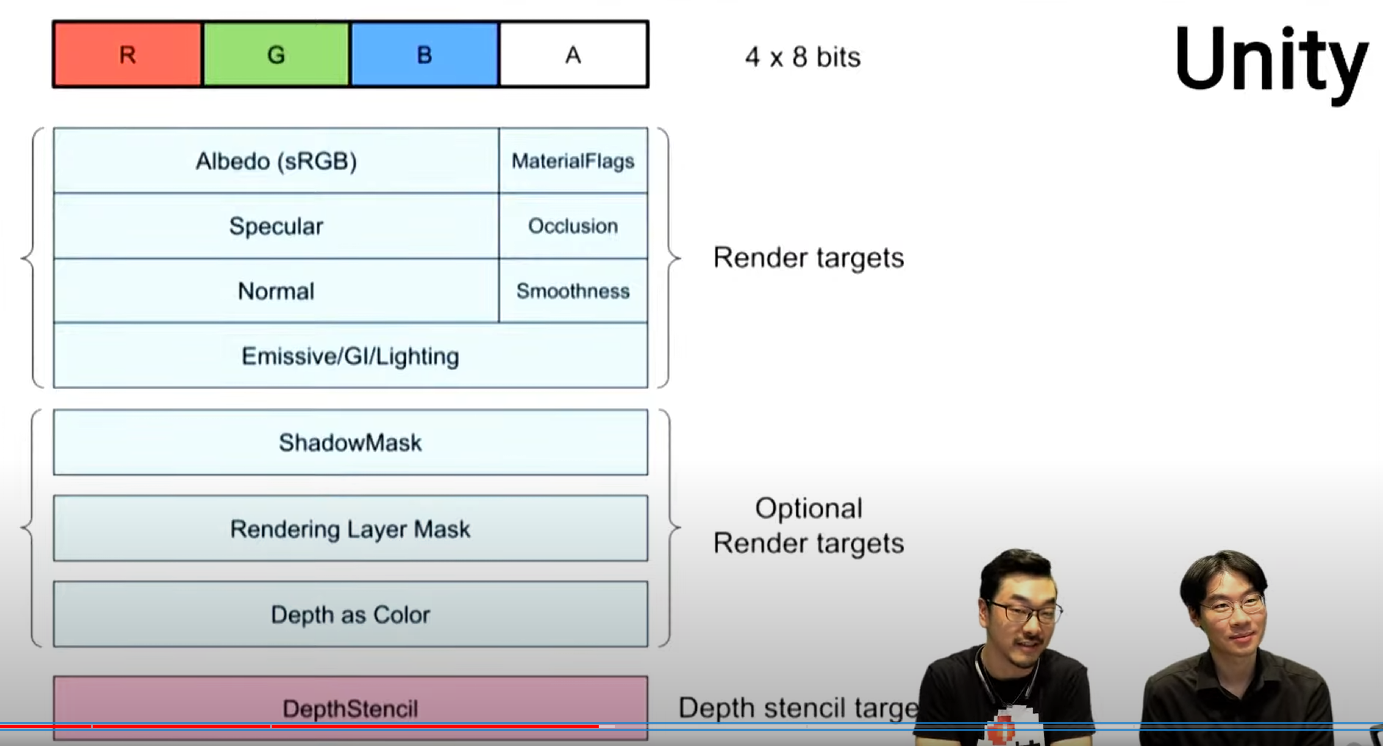
오브젝트를 하나하나 그릴 때마다, 버퍼를 여러개(보통 3~4개) 만든다.
라이팅에 필요한 속성을 저장한 버퍼를 Geometry Buffer(G-Buffer)라고 함
그러고 나서 라이팅 연산을 하게 됨
DrawCall 3번이 아니고, 세 개의 Render target에 데이터 저장 (MRT - Multi Render Targets)
근데 한 번에 세 개 그리다보니까 대역폭 이슈가 생김

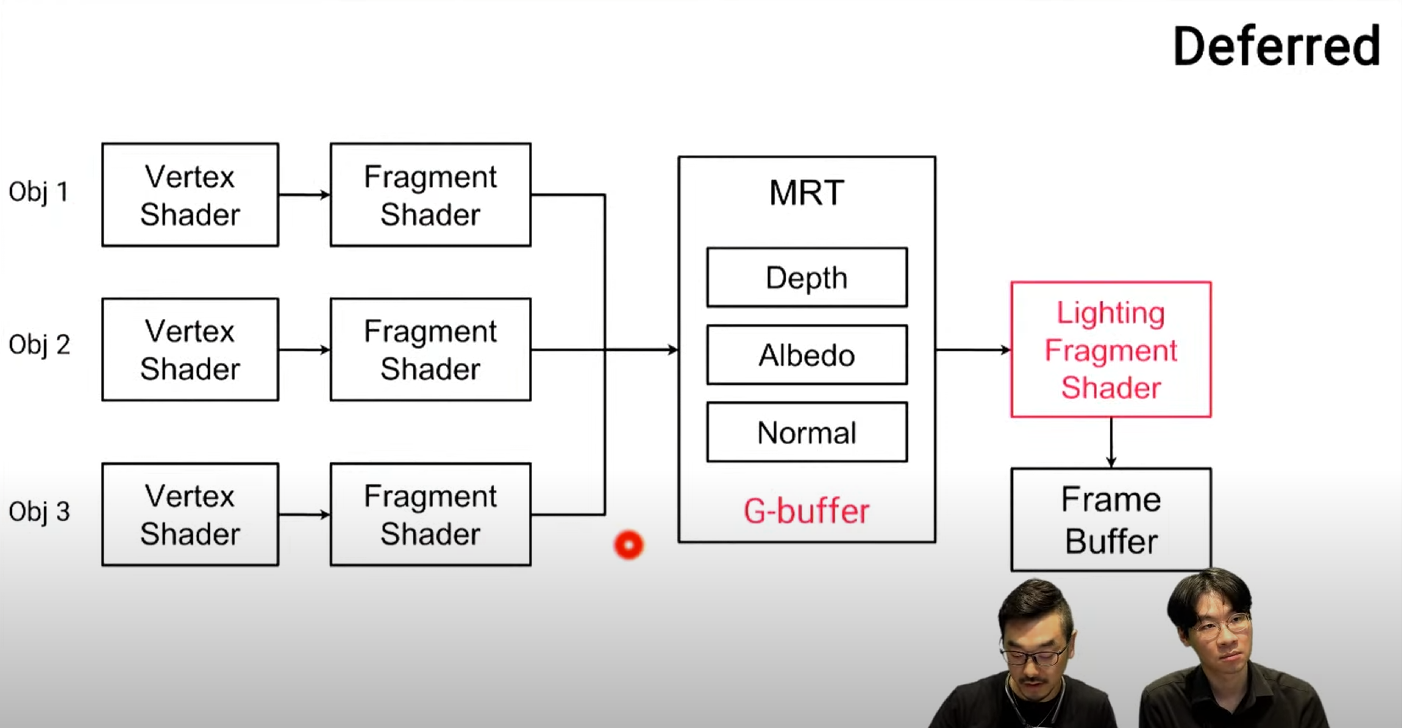
Forward는 하나하나
Deferred는 G Buffer에 저장해두고 라이트는 Screen Space에서 나중에 처리 - 오브젝트나 빛의 개수에 종속되지 않음
G-Buffer의 취약점
머터리얼 다양성의 한계
모든 걸 커버할 수 없다
메모리 대역폭(가장 큰 문제, 모바일..)
Tile-Based GPU (TBR)

타일 단위로 쪼개서 렌더링 하는 방법(Tile Buffer을 거친다)
하나의 타일 위에 오브젝트를 그리고, 이 타일을 프레임 버퍼에 복사
모바일!
Tile Buffer
SRAM으로 구성되어있어 굉장히 빠르다(Frame Buffer는 DRAM)
대신 용량이 적다
GPU->SRAM 은 대역폭 문제 X
GPU->DRAM 은 대역폭 문제 O
Tile-Based Deferred GPU (TBDR)

DDR - VRAM
GPU - GPU에 붙어있는 SRAM
Vertex Shader에서 DrawCall 정보들을 Geometry Working Set(Buffer 개념)에 저장해놓음
-> DrawCall을 날렸다고 바로 Fragment나 Tile Buffer을 사용하는게 아님
다 쌓이고 나면 그 후에 Fragment Shader을 거친다.(지연시켜서)
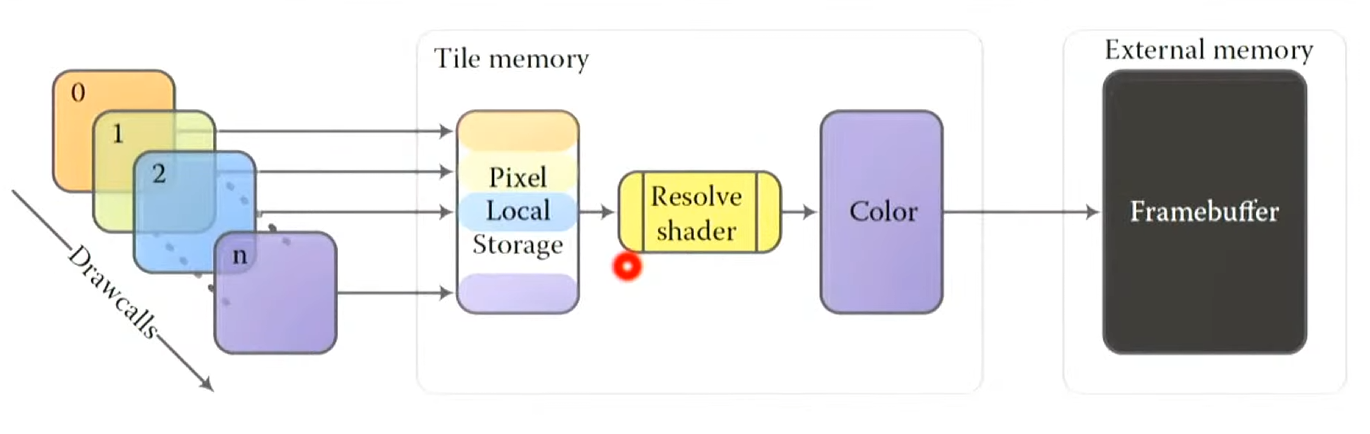
위에 DrawCall 저장하는게 Tile memory에 누적
PLS(Pixel Local Storage)
타일 메모리가 타일 데이터를 저장하기 위해 나왔던건데, PLS라는 개념이 도입되면서 확장해서 개발자가 Storage로 활용 가능
이걸 활용해서 G-Buffer을 여기다 저장
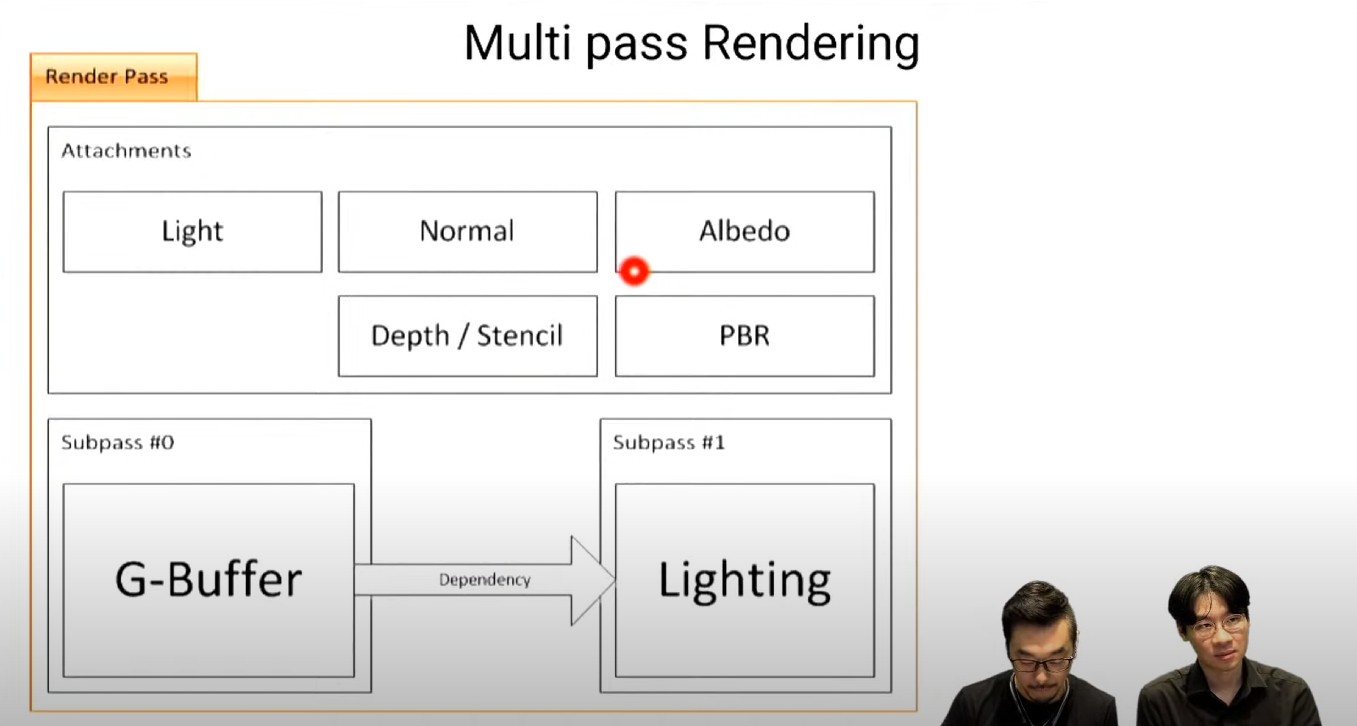
G-Buffer -> Lighting (Dependency)
G-Buffer가 완성 되어야 라이팅 가능
Dependency가 걸려있는 친구들은 하나로 묶을 수도/나눌 수도 있다
-> 타일별로 작동하게 할 수 있다!
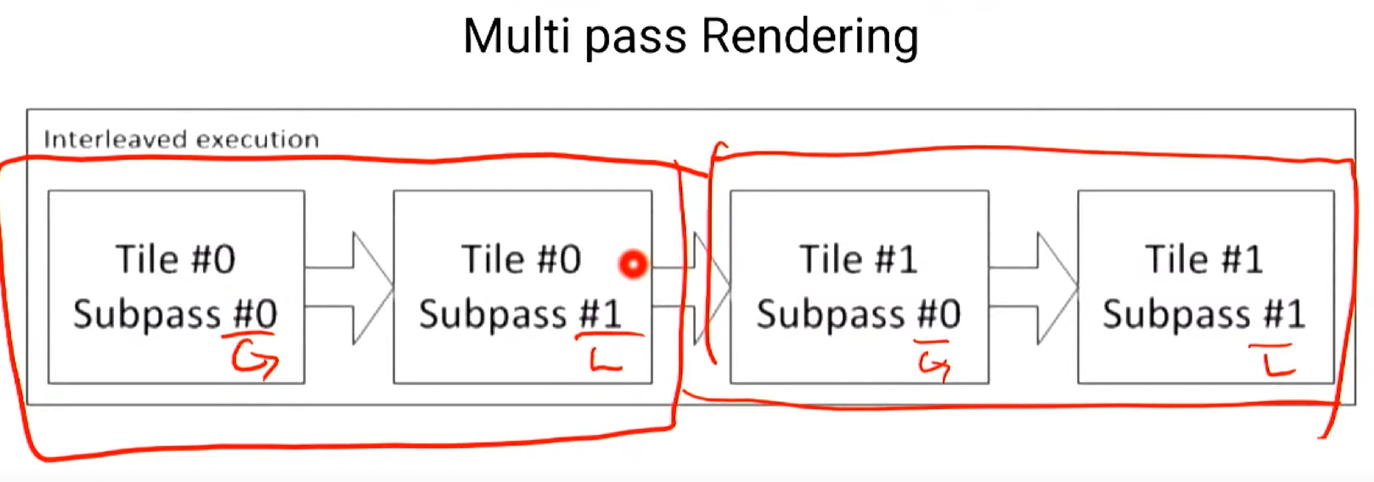
이렇게 되면 타일별로 Deferred Rendering을 해줄 수 있게 된다
하나의 프레임 버퍼를 왔다갔다 하는게 아니라, 타일 내에서 G-Buffer, Lighting Pass를 끝내고 프레임 버퍼로 이동
대역폭 절약 가능!
하지만 타일 가속이 깨지는 경우(다 안그렸는데 프레임 버퍼로 넘어감)가 있기 때문에 완벽하게 작동하진 않는다구한다,,

이거 켜줘야함
Depth Texture Mode
타일에서 다 처리하고나서 Frame Buffer에서 처리하게 되는데, 기본값(Opaque)으로 해놓으면 Opaque만 그리고 넘기고 프레임 버퍼로 넘기면 또 다시 타일 처리하면서 Alpha 오브젝트 그리고 프레임 버퍼 가고 그러는 일이 생김
대역폭 문제가 생길 수 있기 때문에 After Transparents로 해놓는게 좋다

MSAA의 좋은 점
하드웨어 가속을 받을 수 있다! (빠르고 품질도 좋다)
하지만,, Deferred에서는 사용을 못하고 포스트 프로세싱으로 작동하는 FXAA 같은 친구들만 쓸 수 있다
Forward+ (Tiled Forward Shading)
타일 기반(이거는 GPU 타일이 아니라 소프트웨어적인 타일이라고 한다)
라이트를 관리하기 위한 타일

우측 하단이 Forward+ 좌측 상단이 그냥 Forward인데
F+ 보면 타일별로 쪼개고, F는 오브젝트 별로 나눔

Global Light List
라이팅 관리하는 리스트(씬에 있는 라이트들 중 컬링된 결과물들)
Light Grid의 맨 윗 칸은 Index Lists의 offset/size를 의미

Forward+는 라이트만 타일로 관리하는 부분이 추가됨
Light Culling
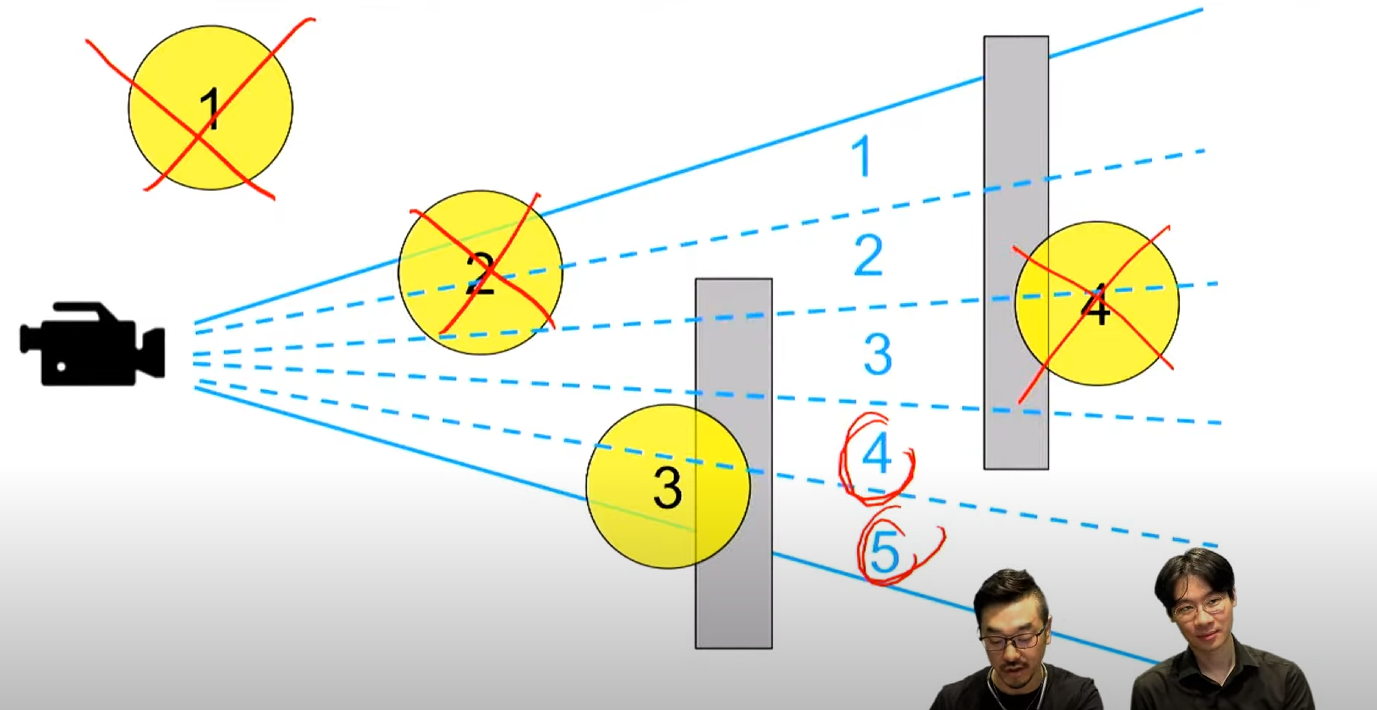
1 - 프리스텀 밖이라 안 그림
2 - 맺히는 오브젝트가 없으니 안 그림
4 - 뒤에 있으니 안 그림

F+의 경우 빛 처리 방법
Index에서 갖고 와서 루프를 돌음
여기서는 Light Count가 의미가 없다(어차피 다 쓰니까, 위에서 설정했던 8이 맥스였던 그것도 의미가 없다 제한이 없기 때문에)

SIMD(Single Instruction Multi Data)
멀티 코어
여러 개의 데이터를 한 번에 연산함
결론
'Study > Graphics' 카테고리의 다른 글
| 효율적인 텍스쳐 압축 이해하기 (1) | 2024.09.05 |
|---|